Towards heterogeneous parallelism for SPHinXsys (Part 3)
Xiangyu Hu and Alberto Guarnieri
Performance Evaluation
The dam-break flow simulation which very often has been used as reference is chosen as the benchmark test-case. Additionally, simulations have been executed with single and double floating-point precision. Computations are carried out on a workstation composed of two Intel Xeon E5-2603 v4 and one NVIDIA GeForce RTX 2080 Ti. Results presented in Figs 1 and 2 delineate a performance improvement up to 27 times the execution on CPU using single precision.
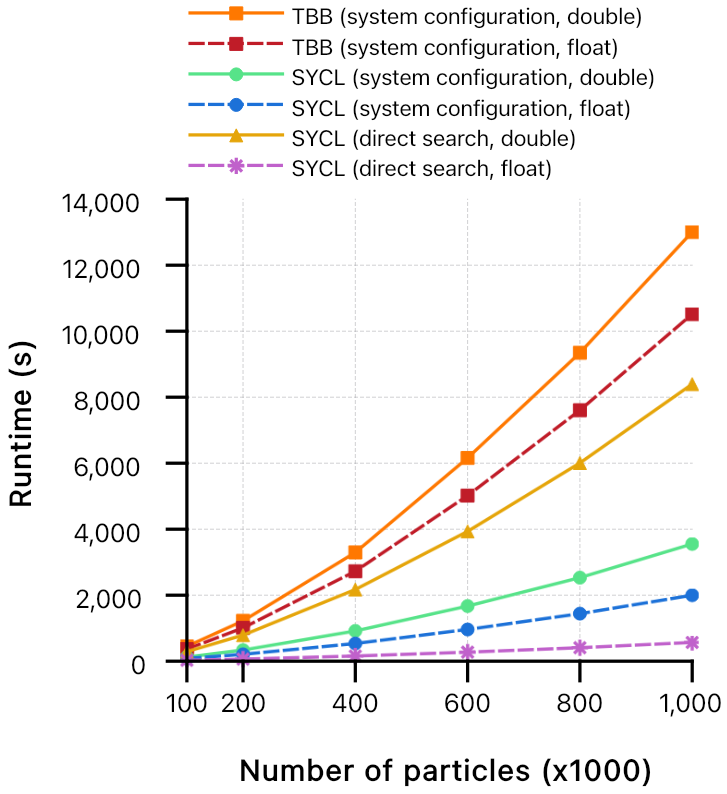
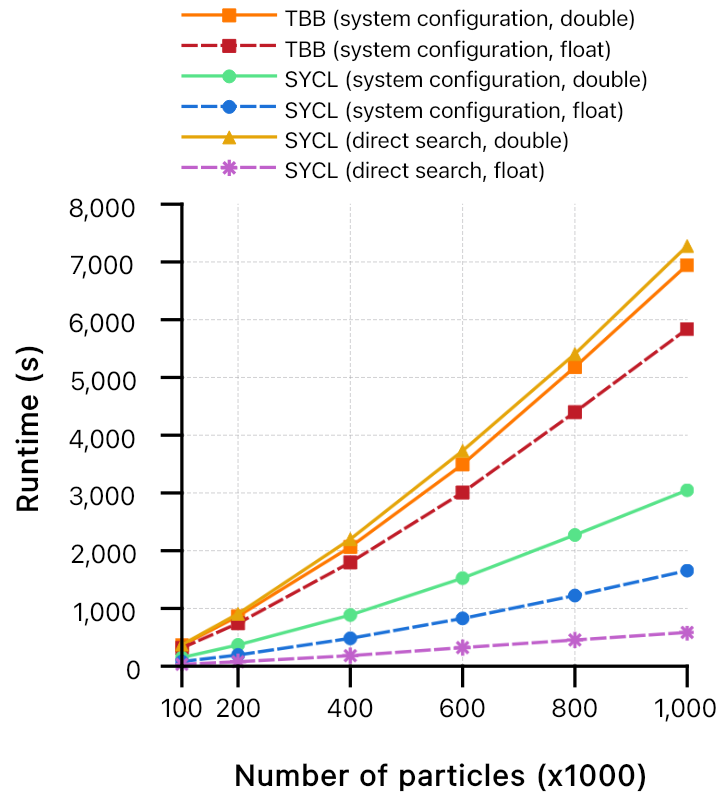
In particular, it is clear how single floating-point precision on GPU runs considerably better than any other configuration when executed using direct search.
In order to compare the achieved results with an existing GPU parallelization of SPH, SPHinXsys has been tested against DualSPHysics, an SPH solver parallelized with CUDA. The test-case defined by Kleefsman et al. is used to compare the two implementations. The baseline results of DualSPHysics have been taken from an existing benchmark involving the same test-case. In particular, the results considered are simulation executed on an NVIDIA RTX 2080Ti. The same test-case has been replicated in SPHinXsys and simulated on the same GPU.
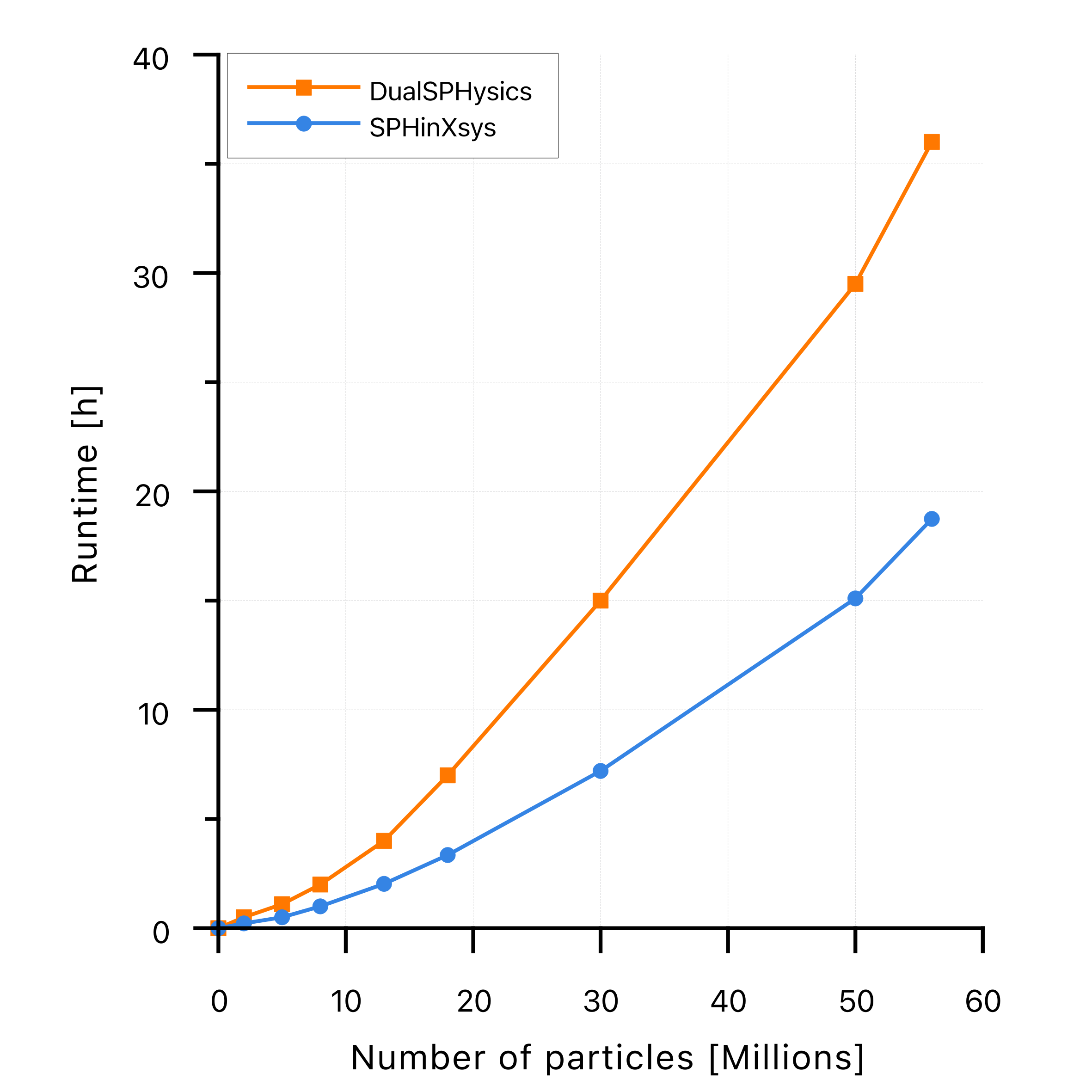
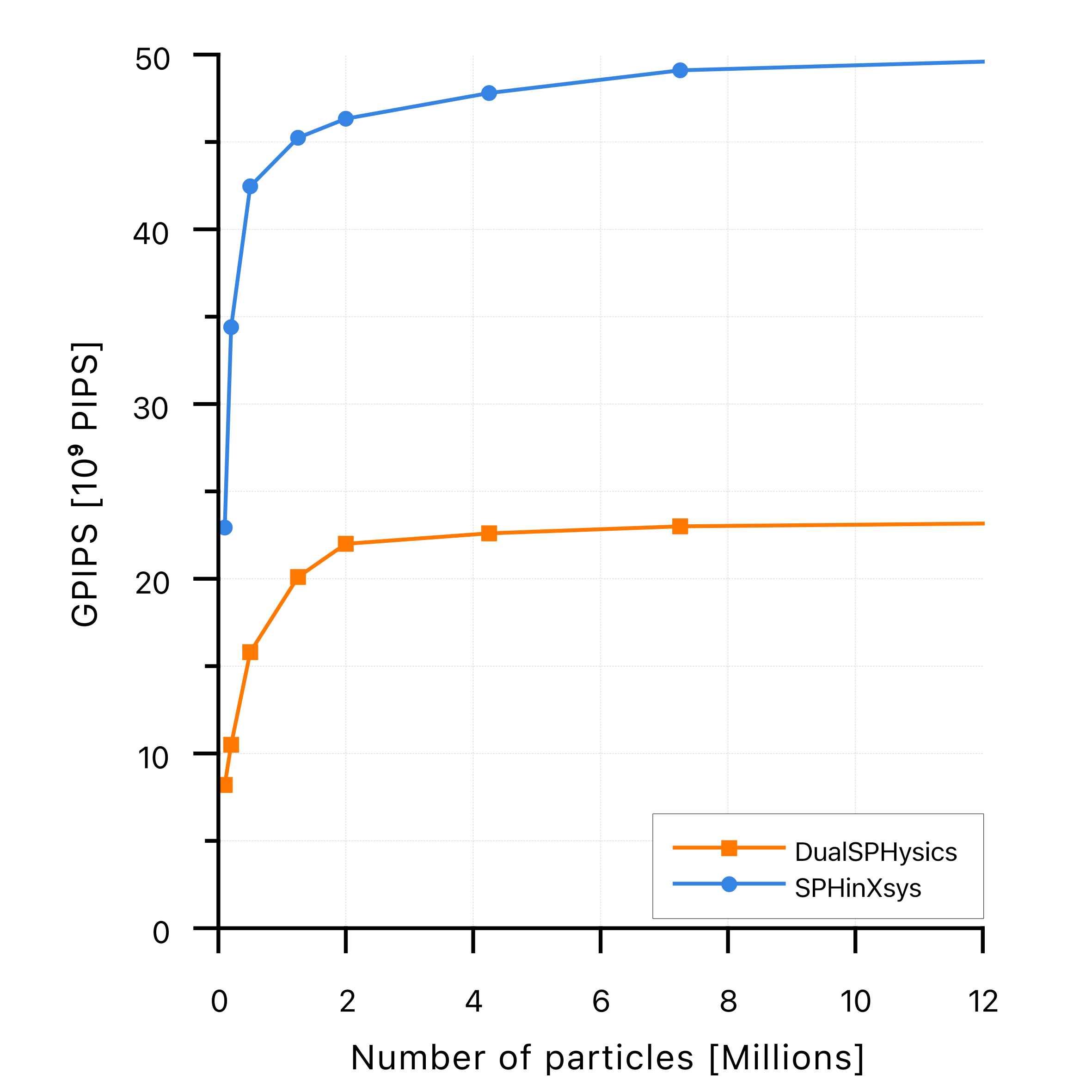
Results are presented in Fig. 3, and they show a SPHinXsys runtime that is half of the one needs by DualSPHysics. Specifically, for the case with the maximum number of particles of 56 million, while DualSPHysics is able to computed the first two seconds of the simulation in 32 hours, SPHinXsys simulates the same period in 18 hours. To confirm such results, Giga Particle Interactions Per Second (GPIPS) has also been computed, which is considered by Dom'inguez et al. a better unit of measurement compared to pure runtime. The latter could in fact be affected by different timestep sizes, I/O output, etc. It is found that SPHinXsys GPIPS are twice the amount of DualSPHysics, effectively confirming the runtime results, as shown in Fig. 4.
Conclusions
We presents the realization of heterogeneous parallelism for SPHinXsys based on the SYCL standard for GPU computing. This is motivated by the expectation that, besides accelerating the SPH simulation and easy programming and maintaining, SPHinXsys is still able to maintain the already offered benefits for open-source based development without notable compensation.
As the present implementation are actually more on generalizing the usage of data types so that single computing kernel can be executed on host and device, sequenced or parallelized, other than the exact numerical algorithm itself. Heterogeneous parallelism is achieved with the minimum modification of the original program pattern. This is especially suitable for the engineer developer as they do not need understand execution details of the numerical method they are developing.
Another advantage is that, since generally only a single source code for the computing kernel to be executed with all execution policies, SPHinXsys allows for the development and testing of numerical methods even within the environments without GPUs or even DPC++ installed. If the source code for a computing kernel is crafted following our specified guidelines and prove functional in a standard platform, e.g. Linux system using the GNU compiler, they will seamlessly operate in environments equipped with DPC++ and GPU support.